
Vull anar aprofundint en el tema de la veu generada per IA i la seva implementació a la ràdio i avui vull començar pels inicis
Fa anys que escolto la ràdio en totes les bandes de freqüència. Als anys vuitanta i noranta era soci de la ADXB (Associació DX Barcelona)

El que més m’agradava era la revista que editaven i enviaven a casa. Hi trobaves tot de freqüències concretes per escoltar emissores llunyanes.
Llavors ja sentia sovint veus clarament sintètiques. Algunes deien números i d’altres passaven el part meteorològic. Segurament moltes d’aquelles veus que escoltava eren de la NOAA Weather Radio, una xarxa pública nord-americana dedicada a difondre informació meteorològica i alertes d’emergència.
NOAA Weather Radio (NWR), un exemple pioner
La NOAA Weather Radio (NWR) és una xarxa pública de ràdio dels Estats Units dedicada exclusivament a informació meteorològica i avisos d’emergència. Depèn del National Weather Service, que forma part de la National Oceanic and Atmospheric Administration. Darrere hi ha, doncs, informació totalment fiable. Cobreixen aproximadament el 95% de la població dels Estats Units amb més de 1000 transmissors diferents.
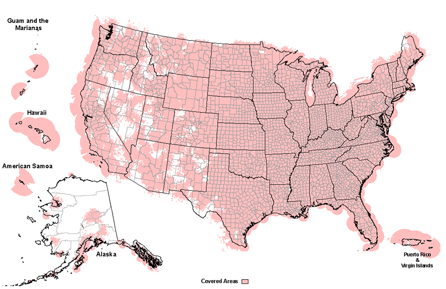
Aquesta és una ràdio diferent. Està pensada per la seguretat pública en un país extens on hi ha tempestes, huracans, tornados i inundacions. Així doncs, a banda de la informació meteorològica, es donen alertes i avisos de protecció civil en unes freqüències on necessites un receptor capaç de sintonitzar la banda VHF meteorològica (162 MHz) i que és molt usual en professionals del transport, mariners o serveis d’emergència.

Curiosament, la població general també utilitzen uns receptors especials amb alarma automàtica per escoltar-la. Sempre estan en silenci i s’activen només quan hi ha un avís important, encara que sigui de nit.
La veu sintètica, una identitat sonora de servei públic reconeguda per la població americana
En aquest cas concret no estem parlant d’una veu generada per IA, és una eina «text to speech» que funciona de fa molts anys, però que em serveix per explicar la naturalitat amb la qual la població nord-americana l’ha abraçat i l’ha acceptat.
Als anys vuitanta el National Weather Service va automatitzar les emissions meteorològiques amb una eina «text to speech» que llegia els textos dels meteoròlegs. I va començar amb una veu que va durar dècades. Va ser coneguda com a «Paul» o «Perfect Paul».
Però, hi ha hagut més veus. Al sud dels Estats Units ha funcionat la veu coneguda com Javier, que dona la informació en español.
També hi ha veus femenines, com Donna.
Per últim, us mostro com sona ara «Paul», que es diu «New Paul«.
Per què les veus sintètiques funcionen tan bé a la ràdio
Aquestes veus, a més, tenen una característica molt curiosa: funcionen especialment bé en ràdio analògica amb mala recepció i en qualsevol condició d’escolta. Té pauses molt clares, síl·labes separades i la velocitat sempre és la mateixa. Quan la recepció per ràdio és dolenta i hi ha soroll de fons, aquest ritme ajuda el cervell a reconstruir la frase. És a dir, s’ha demostrat que les veus de servei artificials són més entenedores pels humans que ho escolten. És fàcil imaginar que les veus generades per IA poden millorar encara més aquest tipus de servei perquè s’escolti a la perfecció al cotxe o amb la ràdio de fons. Sigui com sigui, la NOAA Weather Radio demostra una cosa interessant: el públic ja fa dècades que conviu amb veus artificials a la ràdio quan la funció és clara i útil.





Deja un comentario